
In this post, we will explore the mammogram dataset from the UCI Machine Learning Repository to learn how to predict malignant tumors using different ML classifiers. The point is to compare and contrast the different classifiers to find the best one. This is a good use case where we analyze the small dataset before deploying it at scale. This is the EDA where we perform analysis on a small portion of the dataset to decide on the best ML algorithm to use.
We will be using the mammogram dataset from the UCI Machine Learning Repository. The dataset contains 961 instances and 6 attributes, including the target variable. The goal is to predict the presence of a mass in the mammogram, a binary classification task.
There are several classifiers we can use. However, we will be comparing the results of three classifiers: Deep Neural Network (DNN), Random Forest, and XGBoost. We will also be using Stratified K-Fold cross-validation to ensure a fair comparison of the classifiers.
The reason for choosing these classifiers is that they are widely used and have distinct characteristics. The DNN is a deep learning model that can capture complex, non-linear relationships. Random Forest is an ensemble of decision trees, known for its stability against outliers, avoiding overfitting, ability to generalize well, and ability to handle categorical features. XGBoost is a gradient boosting algorithm that excels in performance and speed, particularly with large datasets. When the dataset has a large number of categories, then XGBoost is a good choice. However, if it performs poorly on a smaller dataset, there is no need to choose XGBoost over Random Forest. Higher speed should not come at the cost of accuracy.
To begin our analysis, we make sure we ingest the data correctly. Since the dataset is in a zip file containing data and a summary, which is normal for most ML datasets, we have to extract and locate the actual data in the zip. You can skip the next section if you are interested in the classifiers only. For MLEs and data scientists, it is of interest to see the data ingestion pipeline.
Handling ZIP Files and Data Extraction
import pandas as pd
from io import BytesIO
from zipfile import ZipFile
import requests
# Load and extract data from ZIP file
url = 'https://archive.ics.uci.edu/static/public/161/mammographic+mass.zip'
response = requests.get(url)
with ZipFile(BytesIO(response.content), 'r') as zip_file:
with zip_file.open('mammographic_masses.data') as file:
masses_data = pd.read_csv(file)
In the above code, we are using the requests library to download the zip file from the UCI Machine Learning Repository. We then use the ZipFile class from the zipfile module to extract the data from the zip file. The data is then read into a pandas DataFrame using the read_csv method. The data is now ready for further processing and analysis.
Classifiers at a Glance
We will be testing three distinctive classifiers:
1. Deep Neural Network (DNN)
We will create a DNN model using the Keras API from TensorFlow. The model will have an input layer with 6 neurons and a ReLU activation function, and an output layer with 1 neuron and a sigmoid activation function. The model will be compiled with the Adam optimizer, binary crossentropy loss function, and accuracy as the evaluation metric.
Choice of the Activation Function
The first layer has 6 neurons connected to the input of 4 neurons (which are the 4 categories on which prediction is done). Whatever the number of neurons in the input layer, it should be equal to the number of categories in the dataset.
The 6 neurons need to be activated. We do not want negative values, so we can squash those values and keep only positive values by using the ReLU function. The ReLU activation function is a popular choice for deep learning models due to its simplicity and effectiveness. It helps mitigate the vanishing gradient problem and accelerates convergence.
The output layer has 1 neuron connected to the 6 neurons of the previous layer. This is because we want one output which is positive (1) or negative (0) classification of the feature. Positive if the features suggest a possible malignancy, and negative if the features suggest a benign mass. Since the neurons have continuous values between 0 and 1, we need to squash the values into either 0 or 1. The best function to do this is the sigmoid function. The sigmoid function is a logistic function that squashes the values between 0 and 1. The sigmoid function is the best choice for binary classification tasks.
Choice of the Loss Function
The loss function is a measure of how well the model is performing. The choice of the loss function is crucial, as it guides the model towards the right direction during training. The choice depends on the nature of the problem. The binary crossentropy loss function is a popular choice for binary classification tasks. It measures the difference between the predicted probability distribution and the true probability distribution. The binary crossentropy loss function is well-suited for our mammogram dataset, making it an ideal choice for our DNN model.
Choice of the Optimizer
The Adam optimizer is a popular choice for training deep learning models. It is an extension of the stochastic gradient descent algorithm that computes adaptive learning rates for each parameter. The Adam optimizer is known for its speed and performance, making it a compelling choice for training deep neural networks. This one is conventional, and you can use it for most of the deep learning models.
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
# Model for Deep Neural Network (DNN)
def create_original_model():
model = Sequential()
model.add(Dense(6, input_dim=4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(metrics=['accuracy'], optimizer='adam', loss='binary_crossentropy')
return model
The model architecture is as follows:

2. Random Forest
Random Forest is a powerful ensemble of decision trees recognized for its robust predictions. Its strength lies in stability against outliers, effective management of categorical features, and resilience to overfitting, making it a dependable choice, especially for smaller datasets. The deliberate setting of the random state ensures reproducibility, while the choice of 100 estimators optimizes its performance.
from sklearn.ensemble import RandomForestClassifier
# Model for Random Forest
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
3. XGBoost
XGBoost is a gradient boosting algorithm meticulously designed for speed and optimal performance. Its configuration, incorporating ‘learning_rate’ and ‘n_estimators,’ ensures the delivery of superior results. The establishment of a random state guarantees reproducibility, making XGBoost a compelling choice, particularly for handling large datasets.
from xgboost import XGBClassifier
# Model for XGBoost
xgb_classifier = XGBClassifier(learning_rate=0.1, n_estimators=100, random_state=42)
When to Use Each Classifier
When the dataset is small, Random Forest is a reliable choice. It’s robust, less prone to overfitting, and can handle categorical features with ease. XGBoost, on the other hand, shines with large datasets, offering superior performance and speed. As for DNN, it’s a versatile choice, particularly for complex, non-linear relationships. Its deep architecture can capture intricate patterns, making it a compelling option for image and text data.
Stratified K-Fold and Imbalanced Datasets
The dataset’s imbalances demand careful handling. We will use Stratified K-Fold, a technique that ensures class distribution integrity in each fold. This guarantees a fair evaluation, particularly crucial when dealing with imbalanced datasets.
from sklearn.model_selection import StratifiedKFold
cv_method = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
Cross-Validation Scores and Comparison
from sklearn.model_selection import cross_val_score
import seaborn as sns
import matplotlib.pyplot as plt
# Run cross-validation for each model
dnn_scores = cross_val_score(dnn, X, y, cv=cv_method)
rf_scores = cross_val_score(rf_classifier, X, y, cv=cv_method)
xgb_scores = cross_val_score(xgb_classifier, X, y, cv=cv_method)
# Compile results
results = pd.DataFrame({
'DNN': dnn_scores,
'RandomForest': rf_scores,
'XGBoost': xgb_scores
})
# Plot results using seaborn boxplot
plt.figure(figsize=(10, 6))
sns.boxplot(data=results)
plt.title('Cross-Validation Scores Comparison')
plt.ylabel('Accuracy')
plt.show()
And we get a beautiful boxplot that visually compares the cross-validation scores of our classifiers. The boxplot illuminates the strengths and variations in our classifiers’ performances. The choice was boxplot to highlight the spread of the CV scores and also to demonstrate the mean.

Conclusion
In this study, we conducted an analysis of mammogram data, employing a comprehensive examination of three classification algorithms. The focus extended to a thorough comparison and contrast of these algorithms, evaluating their performance in a simple classification task. Additionally, a detailed exploration of a Deep Neural Network (DNN) was undertaken, emphasizing the architectural considerations relevant to the specified classification task.
Happy coding and exploring the realms of machine learning!
The full code
import pandas as pd
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from scikeras.wrappers import KerasClassifier
from sklearn.preprocessing import StandardScaler
import seaborn as sns
import matplotlib.pyplot as plt
from urllib.request import urlopen
from zipfile import ZipFile
from io import BytesIO
def load_data():
print("Downloading and extracting the ZIP file...")
# Download and extract the ZIP file
zip_url = 'https://archive.ics.uci.edu/static/public/161/mammographic+mass.zip'
response = urlopen(zip_url)
zip_data = BytesIO(response.read())
with ZipFile(zip_data, 'r') as zip_ref:
# Assuming there is only one CSV file in the ZIP file
csv_file_name = zip_ref.namelist()[0]
print(f"Extracting data from {csv_file_name}...")
with zip_ref.open(csv_file_name) as file:
# Read the CSV file into a DataFrame
masses_data = pd.read_csv(file, na_values=['?'],
names=['BI-RADS', 'age', 'shape', 'margin', 'density', 'severity'])
print("ETL: Dropping missing values...")
# Assuming masses_data is your DataFrame
# ETL and handling missing values
masses_data = masses_data.dropna()
all_features = masses_data[['age', 'shape', 'margin', 'density']].values
all_classes = masses_data['severity'].values
# Scaling features
scaler = StandardScaler()
all_features_scaled = scaler.fit_transform(all_features)
return all_features_scaled, all_classes
# Model for Neural Network (DNN)
def create_original_model():
model = Sequential()
model.add(Dense(6, input_dim=4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(metrics=['accuracy'], optimizer='adam', loss='binary_crossentropy')
return model
# Function to run cross-validation and return scores
def run_cv(model, X, y, cv_method):
print(f"Running {model.__class__.__name__} model...")
return cross_val_score(model, X, y, cv=cv_method)
# Main method to compile and plot results
def run():
X, y = load_data()
# Model for Random Forest
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Model for XGBoost
xgb_classifier = XGBClassifier(learning_rate=0.1, n_estimators=100, random_state=42)
# Model for a Deep Neural Network
dnn = KerasClassifier(build_fn=create_original_model, epochs=100, verbose=0)
cv_method = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
# Run cross-validation for each model
dnn_scores = run_cv(dnn, X, y, cv_method)
rf_scores = run_cv(rf_classifier, X, y, cv_method)
xgb_scores = run_cv(xgb_classifier, X, y, cv_method)
# Compile results
results = pd.DataFrame({
'DNN': dnn_scores,
'RandomForest': rf_scores,
'XGBoost': xgb_scores
})
# Plot results using seaborn boxplot
plt.figure(figsize=(10, 6))
sns.boxplot(data=results)
plt.title('Cross-Validation Scores Comparison')
plt.ylabel('Accuracy')
plt.show()
# save the plot
plt.savefig('cross_val_scores.png')
# Run the main method
run()










 is the log return at time t,
is the log return at time t,  is the conditional mean at time t,
is the conditional mean at time t,  is the standardized residual at time t,
is the standardized residual at time t,  is the conditional standard deviation at time t,
is the conditional standard deviation at time t,  is a standard normal random variable,
is a standard normal random variable, 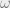 is the constant,
is the constant,  and
and  are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.
are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.





