Exception handling is a crucial aspect of writing robust and reliable code. It allows programmers to gracefully handle unexpected errors and ensure that the program can recover from unforeseen situations. One often overlooked aspect of exception handling is the else clause, which can provide elegant solutions in scenarios where different code paths are needed based on whether an exception occurred. In this blog post, we’ll explore a real-world example where the else clause proved to be a game-changer and helped streamline a data handling process.
The Problem
Consider a scenario where data needs to be fetched, processed, and then saved to a MySQL database. However, there might be instances when the database insertion fails due to network issues, permissions, or other reasons. In such cases, it’s crucial to have a backup plan to prevent data loss. One initial approach could be to stash the data in a CSV file every time there’s an exception during database insertion. However, this approach might lead to unexpected results and unnecessary stashing of data.
The Issue with the Original Approach
Here’s the code that was initially implemented to handle the scenario:
try:
# Save data to MySQL database
database.save_data(df, verbose=verbose)
if os.path.exists('stashed_data.csv'):
# Delete stashed data
if verbose:
print('main: Deleting stashed data CSV file.')
os.remove('stashed_data.csv')
except Exception as e:
print('main: Error saving data to the database.')
print(e)
if verbose:
print('main: Stashing data to CSV file.')
# Save data to CSV file
df.to_csv('stashed_data.csv', index=False)
The issue with this approach is that the stashed data in the CSV file is deleted before handling the exception. As a result, the data is lost even if there was a chance to handle the exception and recover from the error. This approach could potentially lead to unnecessary data loss and complications during troubleshooting.
The Solution
To address the issue and ensure more controlled data handling, the else clause can be utilized. By structuring the exception handling code with an else clause, you can ensure that the data is stashed in the CSV file only when the database insertion operation was successful. If an exception is raised, the else block won’t execute, preventing unnecessary stashing of data.
The Revised Code:
try:
# Save data to MySQL database
database.save_data(df, verbose=verbose)
except Exception as e:
print('main: Error saving data to the database.')
print(e)
if verbose:
print('main: Stashing data to CSV file.')
# Save data to CSV file
df.to_csv('stashed_data.csv', index=False)
else:
if os.path.exists('stashed_data.csv'):
# Delete stashed data
if verbose:
print('main: Deleting stashed data CSV file.')
os.remove('stashed_data.csv')
Conclusion
In software development, making the right decisions in exception handling can greatly impact the reliability and maintainability of your code. The else clause provides an elegant way to differentiate between code paths where an exception occurred and where it didn’t. By utilizing the else clause, as demonstrated in our practical use case, you can avoid unnecessary data stashing and ensure a more efficient and robust data handling process. Remember, sometimes, less is more, and a single keyword like else can make a world of difference in the outcome of your code.
Managing and organizing a music collection often involves keeping track of the artist and song information associated with each MP3 file. Manually updating ID3 tags can be a time-consuming task, especially when dealing with a large number of files. However, with the power of Python and the Mutagen library, we can automate this process and save valuable time. In this article, we will explore a Python script that updates ID3 tags for MP3 files based on the filename structure.
Prerequisites:
To follow along with this tutorial, make sure you have Python and the Mutagen library installed on your system. You can install Mutagen by running pip install mutagen in your terminal.
Understanding the Code:
The Python script we’ll be using leverages the Mutagen library to handle ID3 tag manipulation. The core logic resides in the update_id3_tags function, which updates the ID3 tags of an MP3 file based on the filename structure.
The script accepts command-line arguments using the argparse module, allowing you to specify the folder containing your MP3 files, along with options to ignore files with existing ID3 tags and print verbose output. This provides flexibility and customization to suit your specific requirements.
The getargs function parses the command-line arguments and returns the parsed arguments as an object. The folder_path, ignore_existing, and verbose variables are then extracted from the parsed arguments.
The script retrieves a list of MP3 files in the specified folder and iterates over each file. For each file, the update_id3_tags function is called. It extracts the artist and song name from the filename using the specified structure. The ID3 tags are then updated with the extracted information using the Mutagen library.
Code:
#!/usr/bin/env python
import os
import argparse
from mutagen.id3 import ID3, TIT2, TPE1
def update_id3_tags(filename, ignore_existing, verbose):
# Extract artist and song name from filename
basename = os.path.basename(filename)
print(f"processing --[{basename}]--")
if "-" in basename:
artist = basename[:-4].split(" - ")[0].strip()
song = " - ".join(basename[:-4].split(" - ")[1:]).strip()
else:
print("Cannot split file not in format [artist] - [song].mp3")
return -1
# Load the ID3 tags from the file
audio = ID3(filename)
# Check if ID3 tags already exist
if not ignore_existing or not audio.tags:
# Update the TIT2 (song title) and TPE1 (artist) tags if they are empty
if not audio.get("TIT2"):
audio["TIT2"] = TIT2(encoding=3, text=song)
if verbose:
print(f"Updated TIT2 tag for file: {filename} with value: {song}")
elif verbose:
print(f"Skipping existing ID3 tag for title: {audio.get('TIT2')}")
if not audio.get("TPE1"):
audio["TPE1"] = TPE1(encoding=3, text=artist)
if verbose:
print(f"Updated TPE1 tag for file: {filename} with value: {artist}")
elif verbose:
print(f"Skipping existing ID3 tag for track: {audio.get('TPE1')}")
print('-'*10)
# Save the updated ID3 tags back to the file
audio.save()
def getargs():
# parse command-line arguments using argparse()
parser = argparse.ArgumentParser(description='Update ID3 tags for MP3 files.')
parser.add_argument("folder", nargs='?', default='.', help="Folder containing MP3 files (default: current directory)")
parser.add_argument('-i', "--ignore", action="store_true", help="Ignore files with existing ID3 tags")
parser.add_argument('-v', "--verbose", action="store_true", help="Print verbose output")
return parser.parse_args()
if __name__ == '__main__':
args = getargs()
folder_path = args.folder
ignore_existing = args.ignore
verbose = args.verbose
# Get a list of MP3 files in the folder
mp3_files = [file for file in os.listdir(folder_path) if file.endswith(".mp3")]
# Process each MP3 file
for mp3_file in mp3_files:
mp3_path = os.path.join(folder_path, mp3_file)
update_id3_tags(mp3_path, ignore_existing, verbose)
Example:
Let’s assume you have a folder called “Music” that contains several MP3 files with filenames in the format “artist – song.mp3”. We want to update the ID3 tags for these files based on the filename structure.
Here’s how you can use the Python script:
python script.py Music --ignore --verbose
In this example, we’re running the script with the following arguments:
Music: The folder containing the MP3 files. Replace this with the actual path to your folder.
--ignore: This flag tells the script to ignore files that already have existing ID3 tags.
--verbose: This flag enables verbose output, providing details about the files being processed and the updates made.
By running the script with these arguments, it will update the ID3 tags for the MP3 files in the “Music” folder, ignoring files that already have existing ID3 tags, and provide verbose output to the console.
Once the script finishes running, you can check the updated ID3 tags using any media player or music library software that displays the ID3 tag information.
This example demonstrates how the Python script automates the process of updating MP3 ID3 tags based on the filename structure, making it convenient and efficient to manage your music collection.
Conclusion:
Automating the process of updating MP3 ID3 tags can save you valuable time and effort. With the Python script we’ve discussed in this article, you can easily update the ID3 tags of your MP3 files based on the filename structure. The flexibility offered by command-line arguments allows you to tailor the script to your specific needs. Give it a try and simplify your music collection management!
If you’re a Python developer who finds themselves juggling multiple Python versions on an Ubuntu system, you may have noticed that the deadsnakes ppa doesn’t provide install candidates for kinetic (22.10). This can be a frustrating roadblock, especially if you’re trying to work with Tensorflow extended (TFX), which doesn’t cooperate smoothly with Python 3.10.
Fortunately, there’s a solution: pyenv. Pyenv is a remarkable tool that simplifies the installation, management, and switching between different Python versions effortlessly. In this blog post, we’ll walk you through the process of installing pyenv on Ubuntu, empowering you to effortlessly manage multiple Python versions on your system.
Step 1: Update System Packages
Before installing pyenv, we need to update the system packages to their latest version. Run the following command to update the system packages:
sudo apt update && sudo apt upgrade -y
Step 2: Install Dependencies
pyenv requires some dependencies to be installed on your system. Run the following command to install the dependencies:
Once the dependencies are installed, we can proceed with the installation of pyenv. Run the following command to install pyenv [1]:
curl https://pyenv.run | bash
This command will download and install the latest version of pyenv on your system. Once the installation is complete, add the following lines to your ~/.bashrc file to set up pyenv [2]:
Then, run the following command to reload your ~/.bashrc file:
source ~/.bashrc
Depending on your setup, you may have one or more of the following files: ~/.profile, ~/.bash_profile or ~/.bash_login. If any of these files exist, it is recommended to add the commands there. However, if none of these files are present, you can simply add the commands to ~/.profile for seamless integration.
Step 4: Verify Installation
To verify that pyenv is installed correctly, run the following command:
pyenv --version
This command should output the version number of pyenv installed on your system.
Step 5: Install Python
Now that pyenv is installed, you can use it to install any Python version you need. To install Python 3.9.0, for example, run the following command:
pyenv install 3.9.0
This will download and install Python 3.9.0 on your system. Once the installation is complete, you can set this version of Python as the default by running the following command:
pyenv global 3.9.0
Step 6: Set Up a Virtual Environment
Now that you have installed pyenv, you can use it to create and manage virtual environments for your Python projects. To create a virtual environment for your project, run the following command:
pyenv virtualenv 3.9.0 tfx_venv
This command will create a new virtual environment named tfx_venv, based on Python 3.9.0. The virtual environment will be stored at $HOME/.pyenv/versions/3.9.0/tfx_venv .
Pyenv’s standout feature lies in its ability to set specific environments based on individual folders. Imagine a scenario where you require Python 3.9 for your trading-gcp folder, while the rest of your projects calls for Python 3.10.
With pyenv, achieving this is a breeze. Simply navigate to the trading-gcp folder and run the command
pyenv local tfx_venv
Pyenv will automatically configure the environment to match your folder’s requirements. This is accomplished by creating a .python-version file within the folder, which references the tfx_venv environment.
If we want to reset the python environment associated with this folder then we simply need to remove this file or run another pyenv local command.
Managing virtual environments becomes hassle-free with pyenv. You no longer need to worry about manual activation or deactivation. As you navigate to different folders, pyenv seamlessly adjusts the Python environment to suit the code contained within. When you leave the folder, the environment switches back automatically.
Conclusion
In this tutorial, we have gone through the steps to install pyenv on Ubuntu. pyenv is a useful tool that can help you manage multiple Python versions on your system with ease. With pyenv, you can switch between different Python versions and install the required packages for each version without any conflicts.
Are you struggling with visualizing or analyzing data that is noisy or contains irregularities? Do you need to identify trends that may not be immediately apparent to the naked eye or require an analytical approach? One way to address these challenges is by using a spline, a mathematical function that smoothly connects data points. Splines can be used to “smooth out” data, making it easier to analyze and visualize.
In this blog post, we will explore the use of the UnivariateSpline function in Python’s scipy.interpolate library to fit a spline to noisy data. Spline interpolation is a method of interpolating data points by fitting a piecewise-defined polynomial function to the data.
In Python, the scipy.interpolate module provides several functions for fitting splines to data. One of these functions is UnivariateSpline, which fits a spline to a set of one-dimensional data points.
Let’s take a closer look at how UnivariateSpline works and how it can be used to smooth out noisy data in Python. We’ll use an example code snippet to illustrate the process.
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import UnivariateSpline
x = np.linspace(0, 10, 100)
y1 = 0.2*x + 0.5*np.sin(x) + 2*np.random.normal(0, 0.1, size=100)
xs = np.linspace(np.min(x), np.max(x), 1000)
In this code, we first import the necessary modules: numpy, matplotlib.pyplot, and scipy.interpolate. We then create a set of x values using numpy.linspace(), which generates a linearly spaced array of 100 values between 0 and 10. Then, we generate some noisy data points using numpy’s linspace and random functions:
Next, we define the range of our x-axis by creating a new array, xs, with 1000 evenly spaced points between the minimum and maximum x values:
Now, we use the UnivariateSpline function to fit a spline to the noisy data:
spl = UnivariateSpline(x, y1)
We then plot the original data points and the fitted spline with all default parameters:
fig, ax = plt.subplots()
ax.plot(x, y1, 'k.', alpha=0.5)
plt.plot(xs, spl(xs), 'b', lw=1)
plt.title("Fitting a spline to noisy data (k=AUTO, smooth=AUTO)")
plt.xlabel('time')
plt.ylabel('Generated Stock prices')
plt.show()
The resulting plot shows that the spline fits the noisy data reasonably well, but there is some room for improvement.
Next, we try fitting the spline with a different degree, k, and a smoothing factor, s:
This time, we use a degree of 4 for the spline and a smoothing factor of 20. The resulting plot shows that the spline fits the data even better than before. Finally, we try fitting the spline with a different smoothing factor:
spl = UnivariateSpline(x, y1)
spl.set_smoothing_factor(1)
fig, ax = plt.subplots()
ax.plot(x, y1, 'k.', alpha=0.5)
plt.plot(xs, spl(xs), 'b', lw=1)
plt.title("Fitting a spline to noisy data (k=AUTO, smooth=1)")
plt.xlabel('time')
plt.ylabel('Generated Stock prices')
plt.show()
This time, we set the smoothing factor to 1. The resulting plot shows that the spline now fits the data too closely, and has likely overfit the data.
By default, UnivariateSpline uses a smoothing factor of 0, which can result in a curve that closely follows the original data points, even if they are noisy or irregular. However, this can also lead to overfitting, where the curve follows the noise rather than the underlying trend in the data.
In conclusion, the UnivariateSpline function in Python’s scipy.interpolate library is a powerful tool for fitting a spline to noisy data. By adjusting the degree of the spline and the smoothing factor, we can achieve a good balance between fitting the data closely and avoiding overfitting. This method helps us draw envelopes around Monte Carlo chains or draw the Snell’s envelope. The possibilities are endless.
Full code
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import UnivariateSpline
x = np.linspace(0, 10, 100)
y1 = 0.2*x + 0.5*np.sin(x) + 2*np.random.normal(0, 0.1, size=100)
xs = np.linspace(np.min(x), np.max(x), 1000)
spl = UnivariateSpline(x, y1)
fig, ax = plt.subplots()
ax.plot(x, y1, 'k.', alpha=0.5)
plt.plot(xs, spl(xs), 'b', lw=1)
plt.title("Fitting a spline to noisy data (k=AUTO, smooth=AUTO)")
plt.xlabel('time')
plt.ylabel('Generated Stock prices')
plt.show()
spl = UnivariateSpline(x, y1, k=4)
spl.set_smoothing_factor(20)
fig, ax = plt.subplots()
ax.plot(x, y1, 'k.', alpha=0.5)
plt.plot(xs, spl(xs), 'b', lw=1)
plt.title("Fitting a spline to noisy data (k=4, smooth=20)")
plt.xlabel('time')
plt.ylabel('Generated Stock prices')
plt.show()
spl = UnivariateSpline(x, y1)
spl.set_smoothing_factor(1)
fig, ax = plt.subplots()
ax.plot(x, y1, 'k.', alpha=0.5)
plt.plot(xs, spl(xs), 'b', lw=1)
plt.title("Fitting a spline to noisy data (k=AUTO, smooth=1)")
plt.xlabel('time')
plt.ylabel('Generated Stock prices')
plt.show()
In time series analysis, it is essential to model the volatility of a stock. One way to achieve this is through the use of the EGARCH (Exponential Generalized Autoregressive Conditional Heteroskedasticity) model. In this article, we will perform an analysis of the MSFT stock price using EGARCH to model its volatility.
GARCH Model and When to Use It
GARCH (Generalized Autoregressive Conditional Heteroskedasticity) is a statistical model used to analyze financial time series data. It is a type of ARCH (Autoregressive Conditional Heteroskedasticity) model that takes into account the volatility clustering often observed in financial data. The GARCH model assumes that the variance of the error term in a time series is a function of both past error terms and past variances.
The GARCH model is commonly used in finance to model and forecast the volatility of asset returns. In particular, it is useful for predicting the likelihood of extreme events, such as a sudden stock market crash or a sharp increase in volatility.
When deciding whether to use a GARCH model, it is important to consider the characteristics of the financial time series data being analyzed. If the data exhibits volatility clustering or other patterns of heteroskedasticity, a GARCH model may be appropriate. Additionally, GARCH models are often used when the goal is to forecast future volatility or to estimate the risk associated with an investment. The GARCH(p,q) model can be represented by the following equation:
where is the log return at time t, is the conditional mean at time t, is the standardized residual at time t, is the conditional standard deviation at time t, is a standard normal random variable, is the constant, and are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.
In a GARCH(p,q) model, the dependence on the error term and the volatility term at the same time reflects the notion of volatility clustering, which is a characteristic of financial time series data. The error term represents the current shock or innovation to the return series, while the volatility term captures the past history of the shocks. The dependence on the error term and the volatility term at the same time implies that the model recognizes that a current shock to the return series can have a persistent effect on future volatility. In other words, large shocks tend to be followed by large subsequent changes in volatility, and vice versa. This feature of GARCH models has important implications for risk management and financial decision-making. By accounting for the clustering of volatility, GARCH models can provide more accurate estimates of risk measures, such as Value-at-Risk (VaR) and Expected Shortfall (ES), which are used to assess the potential losses in financial portfolios. GARCH models can also be used to forecast future volatility, which can be useful for developing trading strategies and hedging positions in financial markets. We will explore these concepts in the future parts of this ongoing series.
One specific form of the GARCH model is the EGARCH model, which stands for Exponential Generalized Autoregressive Conditional Heteroskedasticity. The EGARCH model allows for both asymmetry and leverage effects in the volatility of the data. The EGARCH model can be represented by the following equation:
where is the log return at time t, is the conditional mean at time t, is the standardized residual at time t, is the conditional standard deviation at time t, is a standard normal random variable, is the constant, and are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.
Exploratory Data Analysis
Before modeling, it is essential to explore the data to understand its characteristics. The plot below shows the time series plot of the MSFT stock price.
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import statsmodels.api as sm
import pmdarima as pm
import yfinance as yf
import seaborn as sns
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
msft = yf.Ticker('MSFT')
df = msft.history(period='5y')
sns.light_palette("seagreen", as_cmap=True)
sns.set_style("darkgrid", {"grid.color": ".6", "grid.linestyle": ":"})
sns.lineplot(df['Close'])
plt.title('MSFT')
We can see that the stock price exhibits a clear upward trend over the period, with some fluctuations. The plot below shows the ACF and PACF plots of the first differences of the stock price.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# ACF and PACF plots of first differences
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
plot_acf(msft_log, ax=axes[0])
plot_pacf(msft_log, ax=axes[1])
plt.tight_layout()
plt.show()
From the ACF and PACF plots, we can observe that there is no clear pattern in the data, indicating that it may be a white noise process. However, there is some significant autocorrelation at lag 1 in the PACF plot, suggesting that we may need to include an AR term in our model.
Model Selection
To model the volatility of the MSFT stock price, we will use the EGARCH model. We will begin by fitting a baseline EGARCH(1,1) model and compare it with other models.
from arch import arch_model
# Fit EGARCH(1,1) model
egarch11_model = arch_model(msft_log, vol='EGARCH',
p=1, o=0, q=1, dist='Normal')
egarch11_fit = egarch11_model.fit()
print(egarch11_fit.summary())
Constant Mean - GARCH Model Results
===============================================================
Dep. Variable: Close R-squared: 0.000
Mean Model: Constant Mean Adj. R-squared: 0.000
Vol Model: GARCH Log-Likelihood: 3350.57
Distribution: Normal AIC: -6693.15
Method: Maximum Likelihood BIC: -6672.60
No. Observations: 1258
Date: Tue, May 09 2023 Df Residuals: 1257
Time: 10:42:42 Df Model: 1
Mean Model
===============================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
mu 1.5045e-03 9.713e-08 1.549e+04 0.000 [1.504e-03,1.505e-03]
Volatility Model
===============================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
omega 7.6495e-06 1.791e-12 4.272e+06 0.000 [7.650e-06,7.650e-06]
alpha[1] 0.1000 1.805e-02 5.541 3.004e-08 [6.463e-02, 0.135]
beta[1] 0.8800 1.551e-02 56.729 0.000 [ 0.850, 0.910]
===============================================================
The following table shows the results of fitting various EGARCH models to the MSFT stock price data.
Overall, the models indicate that the volatility of stock returns is persistent, with all models showing significant positive values for the alpha parameters. Moreover, the models suggest that the volatility of stock returns responds asymmetrically to changes in returns, with negative shocks having a more significant impact than positive shocks. This is highlighted by the negative values of the omega parameters in all three models. In finance, the omega parameter represents the risk in the market that is unrelated to the past volatility of the asset being studied. It signifies the inherent uncertainty or randomness in the system that cannot be explained by any of the past information used in the model.
Model
Log Likelihood
AIC
BIC
EGARCH(1,1)
3355.44
-6702.88
-6682.33
EGARCH(1,2)
3356.18
-6702.36
-6676.67
EGARCH(2,1)
3356.67
-6703.34
-6677.66
EGARCH(2,2)
3356.67
-6701.34
-6670.52
Based on the information criteria, the EGARCH(2,2) model has the lowest AIC and BIC values, making it the final model of choice.
Model Diagnostics
After selecting the final model, we need to perform diagnostic checks to ensure that the model is appropriate. The following plots show the diagnostic checks for the EGARCH(2,2) model.
From the residual plot, we can see that the residuals of the model are approximately normally distributed and have constant variance over time. Additionally, the ACF and PACF plots of the residuals show no significant autocorrelation, indicating that the model has captured all the relevant information in the data.
Forecasting
The EGARCH(2,2) model provides a volatility fit for the MSFT stock price. Notably, there were spikes in volatility around the start of COVID in 2020 and during the Fed’s interest rate increase in 2022.
# Forecast next day
forecasts = egarch22_fit.forecast(reindex=False)
print("Forecasting Mean variance")
print(egarch22_forecast.mean.iloc[-3:])
print("Forecasting Residual variance")
print(forecasts.residual_variance.iloc[-3:])
Forecasting Mean variance
h.1
Date
2023-05-09 00:00:00-04:00 0.001541
Based on the model, the forecasted volatility for the next day is 0.001541. This value suggests that the average volatility will decrease compared to the last five days. However, the accuracy of this prediction remains uncertain. To assess the model’s accuracy, a rolling prediction approach can be used and compared against actual values using a measure like RMSE. Further analysis will be explored in the subsequent parts of this series.
References
Tsay, R.S. (2010) Analysis of Financial Time Series, Third Edition. Wiley.
When analyzing data, it is often useful to fit a regression line to model the relationship between two variables. However, it is also important to understand the uncertainty associated with the line of best fit. One way to display this uncertainty is by plotting the confidence interval about the regression line. In this document, we will discuss two methods for plotting the confidence interval about a best fit regression line using R and Python. Finally, we decide on when to use which one.
Method 1: Using R + ggplot2
R is a popular open-source programming language for statistical computing and graphics. To plot the confidence interval about a best fit regression line in R, we can use the ggplot2 package. Here are the steps to do so:
Create a scatter plot with ggplot() and specify the data and variables. The mapping is necessary to let ggplot know that we want to plot the column “a” along the x-axis and the column “b” along the y-axis.
The confidence interval is automatically added. In case it isn’t add the following to the plot: ggplot(df, mapping=aes(x=a,y=b)) + geom_point(shape=18) + geom_smooth(method="lm") + geom_ribbon(aes(ymin=ci[,2], ymax=ci[,3]), alpha=0.2) . The whole code looks like this:
ymin and ymax are the lower and upper bounds of the confidence interval. The alpha parameter adjusts the transparency of the ribbon.
Method 2: Python + seaborn
Python is another popular programming language for data analysis and visualization. To plot the confidence interval about a best fit regression line in Python, we can use the seaborn package. Here are the steps to do so:
Load the necessary libraries:
import pandas as pd
import numpy as np
import seaborn as sns
sns.set_style("whitegrid")
Generate data
a = np.arange(10)
b = 5*a + 5*np.random.rand(10)
df = pd.DataFrame({'a':a, 'b':b})
Create a scatter plot with sns.scatterplot() and specify the data and variables:
_ = sns.scatterplot(data=df, x="a", y="b")
Add the regression line with sns.regplot():
_ = sns.regplot(data=df, x="a", y="b")
Finally, add the confidence interval with sns.regplot(ci=95):
_ = sns.regplot(data=df, x="a", y="b", ci=95)
The ci parameter specifies the confidence interval level in percentage.
Verdict
We used the ggplot2 package in R and the seaborn package in Python to generate the confidence interval plots. The ggplot2 result definitely looks more professional quality while the seaborn was much faster to code. We can choose the method that fits our needs. If we want to publish our graphs in journals then ggplot2 might be a better choice (not always). If we want to do a quick presentation then I will prefer seaborn.
When it comes to time series analysis, it is important to choose the right model to make accurate predictions. Two of the most commonly used models are autoregressive (AR) and moving average (MA). The question is, how do you decide which one to use? One useful tool to help make this decision is the ACF plot.
The ACF (autocorrelation function) plot is a graph that shows the correlation between a time series and its lagged values. It is a measure of how similar a time series is to itself at different points in time. ACF plots can be used to determine whether an AR or MA model is more appropriate for a given time series.
To use ACF plots to decide on AR vs MA models, follow these steps:
Step 1: Determine the order of differencing
The first step is to determine the order of differencing needed to make the time series stationary. Stationarity is important for time series analysis because it ensures that the statistical properties of the time series remain constant over time. To determine the order of differencing, look at the p-value of the ADF test.
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import statsmodels.api as sm
import pmdarima as pm
import yfinance as yf
import seaborn as sns
from statsmodels.tsa.arima.model import ARIMA
msft = yf.Ticker('MSFT')
df = msft.history(period='5y')
sns.light_palette("seagreen", as_cmap=True)
sns.set_style("darkgrid", {"grid.color": ".6", "grid.linestyle": ":"})
sns.lineplot(df['Close'])
plt.title('MSFT')
ADF Test
The Augmented Dickey-Fuller (ADF) test is a statistical test used to determine whether a time series has a unit root, which indicates non-stationarity. Non-stationarity refers to the property of a time series where the statistical properties, such as mean and variance, change over time. The ADF test is commonly used in econometrics and finance to analyze the stationarity of economic and financial data, such as stock prices, interest rates, and exchange rates. The test is named after the econometricians David Dickey and Wayne Fuller, who extended the original Dickey-Fuller test to include additional explanatory variables to improve its statistical power. The ADF test is a popular tool for analyzing time series data and is widely used in academic research and practical applications.
If the p-value of an ADF test is greater than 0.05 then we will need to keep differentiating the series till we reach stationarity. The concept of stationarity will be explained in a separate post. We perform differentiation on a discrete time-series by differencing. pandas diff function will do the trick. We have to keep differencing till the p-value of the ADF test falls below the threshold of 0.05. The number of times we had to perform the diff operation is the order of differencing needed to make the time series stationary.
p = 0.5
df1 = df['Close']
d = 0
while p > 0.05:
p = adfuller(df1)[1]
df1 = df1.diff().fillna(0)
d = d + 1
d = d - 1
print("Difference value (d) for the time-series: ", d)
Difference value (d) for the time-series: 1
Since we are looking at a stock price d=1. Differencing the stock prices once give us a stationary series.
The difference of stock prices does not produce martingles, since difference is not the same as returns. The difference of the log of the stock prices produces a time-series which is normally distributed. This is why stock prices are said to follow a log-normal distribution. We will not concern ourselves with the distribution and focus on the time-series analysis. However, in real world applications we will need to worry about the distribution of the underlying process (Levy processes etc.).
Step 2: Plot the ACF
The second step is to plot the ACF for the time series data. The ACF plot will show the correlation between the time series and its lagged values. The plot will have lag on the x-axis and the correlation coefficient on the y-axis.
plot_acf(df['Close'].diff().fillna(0), lags=20)
Step 3: Look for significant spikes in the ACF plot
After determining the order of differencing, look for significant spikes in the ACF plot. A significant spike is one that is outside the confidence interval. The confidence interval is the range within which the correlation coefficient is likely to fall. If there are significant spikes at lag 1, 2, 3, etc., then an AR model is appropriate. If there are significant spikes at multiple lags, then an ARMA model may be appropriate. If there are significant spikes at lag 0, 1, 2, 3, etc., then an MA model is appropriate.
Step 4: Determine the order of the AR or MA model
The final step is to determine the order of the AR or MA model. This can be done by looking at the significant spikes in the ACF plot. If there is a significant spike at lag 1, then an AR(1) model is appropriate. If there are significant spikes at lag 1 and 2, then an AR(2) model is appropriate. If there is a significant spike at lag 0, then an MA(1) model is appropriate. If there are significant spikes at lag 0 and 1, then an MA(2) model is appropriate. In our case, it seems there is a significant spike at log 0 and no more significant spikes (there is a spurious spike at lag 9 which we can ignore). Therefore, the best mode lfor this time-series will be a MA(1) model. We can verify this conclusion using auto_arima function as well.
AUTO_ARIMA
We can use the auto_arima to find the appropriate ARIMA model. The function finds the right model in the search space by minimizing the AIC of the model.
In conclusion, the ACF plot is a useful tool for deciding on an AR vs MA model for time series analysis. By following the steps outlined above, you can determine whether an AR or MA model is appropriate and the order of the model needed to make accurate predictions.
There are beautiful flowcharts in the book by Peixiero [2] which I found very useful in identifying the time-series model. I am including a variation below.
Peixeiro, M. (2020). Time Series Forecasting Using Python: An introduction to traditional and deep learning models for time series forecasting. Apress.
In today’s fast-paced world, where data is generated at a massive scale, it is essential to process it efficiently and in real-time. This is where the concept of streaming comes into play. Streaming refers to the continuous flow of data, and it is a crucial component of many modern applications and services.
Streaming is required because traditional batch processing techniques are not suitable for handling large volumes of data that need to be processed in real-time. Streaming allows us to process data as it is generated, providing near-instantaneous results.
One example of a service that heavily relies on streaming is Amazon Web Services (AWS). AWS is the to go storage cloud platform for most business, although Azure and GCP are also strong contenders. The basic idea of streaming is the same for all these services. It is instructive to have a knowledge of the process independent of the platform (AWS, GCP).
In this blog post, we will focus on calculating a checksum on streaming data using Python. We will explore how to convert a pandas DataFrame to a text stream and calculate a checksum on it. This approach can be useful for verifying the integrity of data in real-time applications such as data pipelines or streaming APIs.
The data_to_txt_stream function shown above is a Python function that takes in a pandas DataFrame df and converts it into a text stream. The text stream is then returned as a string. This function is useful when dealing with streaming data because it allows us to process the data as it is generated.
The to_csv method of the pandas DataFrame is used to convert the DataFrame to a CSV-formatted string. The resulting CSV string is then converted to a text stream using the io.BytesIO() method. The sep parameter specifies the separator to be used in the CSV file (in this case, a tab character). The header and index parameters specify whether or not to include the header and index in the CSV file, respectively. The quoting parameter specifies the quoting behavior for fields that contain special characters, and the quotechar and escapechar parameters specify the quote and escape characters to use, respectively.
The text stream returned by the function can then be used to calculate a checksum on the data. A checksum is a value that is computed from a block of data and is used to verify the integrity of the data. In the context of streaming data, a checksum can be used to ensure that the data has not been corrupted during transmission.
s3 = boto3.client('s3')
# Create buf object
buf = io.BytesIO()
# Download file to calculate checksum on the file
s3.download_fileobj(bucket_name, object_name, buf)
# Calculate checksum
file_checksum = hashlib.md5(buf.getvalue()).hexdigest()
To calculate a checksum on the text stream, we can use the Python hashlib library. The hashlib library provides various hash functions, such as SHA-256 and MD5, that can be used to compute a checksum on the data. Once the checksum has been computed, it can be compared to the expected checksum to verify the integrity of the data.
In conclusion, the ability to process streaming data efficiently and in real-time is essential in many modern applications and services. The data_to_txt_stream function presented in this blog post provides a way to convert a pandas DataFrame to a text stream, which can be useful when dealing with streaming data. Additionally, computing a checksum on the data can help verify the integrity of the data, which is important in real-time applications such as data pipelines or streaming APIs.
After backing up DVDs we are sometimes forced with the mundane task of renaming files with the episode names. A small python script can automate this laborious task.
/media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/BuffytheVampireSlayer_s01_e01.mp4 [renamed to] /media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/S01 E01 · Welcome to the Hellmouth (1).mp4
/media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/BuffytheVampireSlayer_s01_e02.mp4 [renamed to] /media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/S01 E02 · The Harvest.mp4
/media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/BuffytheVampireSlayer_s01_e03.mp4 [renamed to] /media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/S01 E03 · Witch.mp4
/media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/BuffytheVampireSlayer_s01_e04.mp4 [renamed to] /media/htd/Seagate Backup Plus Drive/TV Shows/Buffy the Vampire Slayer/buffyS01/S01 E04 · Teacher’s Pet.mp4
In this article, we will make a grid of plots in python by iterating over the subplot axes and columns of a pandas dataframe.
Python has a versatile plotting framework in Matplotlib but the documentation seems extremely poor (or I was not able to find the right docs). It took me a fair amount of time to figure out how to send plots of columns of dataframe to individual subplots while rotating the xlabels for each subplot.
Usage
Plotting subplots in Matplotlib begins by using the plt.subplots() statement.
We can omit the nrows and ncols args but I kept it for effect. This statement generates a grid of 2×2 subplots and returns the overall figure (the object which contains all plots inside it) and the individual subplots as a tuple of subplots. The subplots can be accessed using axs[0,0], axs[0,1], axs[1,0], and axs[1,1]. Or they can be unpacked during the assignment as follows.
We, however, do not want to unpack individually. Instead, we would like to flatten the tuple of subplots and iterate over them rather than assigning each subplot to a variable. The tuple is flattened by the flatten() command.
axs.flatten()
We identify 4 columns of a dataframe we want to plot and save the column names in a list that we can iterate over. We flatten the subplots and generate an iterator or we can convert the iterator to a list and then pack it (zip) with the column names.
As we iterate over each subplot axes, and the column names which are zipped with it, we plot each subplot with the ax.plot() command and we have to supply the x and y values manually. I tried plotting with pandas plot df.plot.bar() and assigning the returned object to the ax. It doesn’t work. The x values for the ax.plot() are the dataframe index (df.index) and y values are the values in the dataframe column (which needs to be converted to a list to as ax.plot() does not accept pd.Series).





 is the log return at time t,
is the log return at time t,  is the conditional mean at time t,
is the conditional mean at time t,  is the standardized residual at time t,
is the standardized residual at time t,  is the conditional standard deviation at time t,
is the conditional standard deviation at time t,  is a standard normal random variable,
is a standard normal random variable, 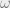 is the constant,
is the constant,  and
and  are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.
are the GARCH and ARCH coefficients at lag i, and p and q are the order of the GARCH and ARCH terms, respectively.













