
In time series analysis, it is essential to model the volatility of a stock. One way to achieve this is through the use of the EGARCH (Exponential Generalized Autoregressive Conditional Heteroskedasticity) model. In this article, we will perform an analysis of the MSFT stock price using EGARCH to model its volatility.
GARCH Model and When to Use It
GARCH (Generalized Autoregressive Conditional Heteroskedasticity) is a statistical model used to analyze financial time series data. It is a type of ARCH (Autoregressive Conditional Heteroskedasticity) model that takes into account the volatility clustering often observed in financial data. The GARCH model assumes that the variance of the error term in a time series is a function of both past error terms and past variances.
The GARCH model is commonly used in finance to model and forecast the volatility of asset returns. In particular, it is useful for predicting the likelihood of extreme events, such as a sudden stock market crash or a sharp increase in volatility.
When deciding whether to use a GARCH model, it is important to consider the characteristics of the financial time series data being analyzed. If the data exhibits volatility clustering or other patterns of heteroskedasticity, a GARCH model may be appropriate. Additionally, GARCH models are often used when the goal is to forecast future volatility or to estimate the risk associated with an investment. The GARCH(p,q) model can be represented by the following equation:

where 




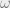


In a GARCH(p,q) model, the dependence on the error term and the volatility term at the same time reflects the notion of volatility clustering, which is a characteristic of financial time series data. The error term represents the current shock or innovation to the return series, while the volatility term captures the past history of the shocks. The dependence on the error term and the volatility term at the same time implies that the model recognizes that a current shock to the return series can have a persistent effect on future volatility. In other words, large shocks tend to be followed by large subsequent changes in volatility, and vice versa. This feature of GARCH models has important implications for risk management and financial decision-making. By accounting for the clustering of volatility, GARCH models can provide more accurate estimates of risk measures, such as Value-at-Risk (VaR) and Expected Shortfall (ES), which are used to assess the potential losses in financial portfolios. GARCH models can also be used to forecast future volatility, which can be useful for developing trading strategies and hedging positions in financial markets. We will explore these concepts in the future parts of this ongoing series.
One specific form of the GARCH model is the EGARCH model, which stands for Exponential Generalized Autoregressive Conditional Heteroskedasticity. The EGARCH model allows for both asymmetry and leverage effects in the volatility of the data. The EGARCH model can be represented by the following equation:

where
Exploratory Data Analysis
Before modeling, it is essential to explore the data to understand its characteristics. The plot below shows the time series plot of the MSFT stock price.
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import statsmodels.api as sm
import pmdarima as pm
import yfinance as yf
import seaborn as sns
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
msft = yf.Ticker('MSFT')
df = msft.history(period='5y')
sns.light_palette("seagreen", as_cmap=True)
sns.set_style("darkgrid", {"grid.color": ".6", "grid.linestyle": ":"})
sns.lineplot(df['Close'])
plt.title('MSFT')

We can see that the stock price exhibits a clear upward trend over the period, with some fluctuations. The plot below shows the ACF and PACF plots of the first differences of the stock price.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# ACF and PACF plots of first differences
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
plot_acf(msft_log, ax=axes[0])
plot_pacf(msft_log, ax=axes[1])
plt.tight_layout()
plt.show()

From the ACF and PACF plots, we can observe that there is no clear pattern in the data, indicating that it may be a white noise process. However, there is some significant autocorrelation at lag 1 in the PACF plot, suggesting that we may need to include an AR term in our model.
Model Selection
To model the volatility of the MSFT stock price, we will use the EGARCH model. We will begin by fitting a baseline EGARCH(1,1) model and compare it with other models.
from arch import arch_model
# Fit EGARCH(1,1) model
egarch11_model = arch_model(msft_log, vol='EGARCH',
p=1, o=0, q=1, dist='Normal')
egarch11_fit = egarch11_model.fit()
print(egarch11_fit.summary())
Constant Mean - GARCH Model Results
===============================================================
Dep. Variable: Close R-squared: 0.000
Mean Model: Constant Mean Adj. R-squared: 0.000
Vol Model: GARCH Log-Likelihood: 3350.57
Distribution: Normal AIC: -6693.15
Method: Maximum Likelihood BIC: -6672.60
No. Observations: 1258
Date: Tue, May 09 2023 Df Residuals: 1257
Time: 10:42:42 Df Model: 1
Mean Model
===============================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
mu 1.5045e-03 9.713e-08 1.549e+04 0.000 [1.504e-03,1.505e-03]
Volatility Model
===============================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
omega 7.6495e-06 1.791e-12 4.272e+06 0.000 [7.650e-06,7.650e-06]
alpha[1] 0.1000 1.805e-02 5.541 3.004e-08 [6.463e-02, 0.135]
beta[1] 0.8800 1.551e-02 56.729 0.000 [ 0.850, 0.910]
===============================================================
The following table shows the results of fitting various EGARCH models to the MSFT stock price data.
Overall, the models indicate that the volatility of stock returns is persistent, with all models showing significant positive values for the alpha parameters. Moreover, the models suggest that the volatility of stock returns responds asymmetrically to changes in returns, with negative shocks having a more significant impact than positive shocks. This is highlighted by the negative values of the omega parameters in all three models. In finance, the omega parameter represents the risk in the market that is unrelated to the past volatility of the asset being studied. It signifies the inherent uncertainty or randomness in the system that cannot be explained by any of the past information used in the model.
| Model | Log Likelihood | AIC | BIC |
| EGARCH(1,1) | 3355.44 | -6702.88 | -6682.33 |
| EGARCH(1,2) | 3356.18 | -6702.36 | -6676.67 |
| EGARCH(2,1) | 3356.67 | -6703.34 | -6677.66 |
| EGARCH(2,2) | 3356.67 | -6701.34 | -6670.52 |
Based on the information criteria, the EGARCH(2,2) model has the lowest AIC and BIC values, making it the final model of choice.
Model Diagnostics
After selecting the final model, we need to perform diagnostic checks to ensure that the model is appropriate. The following plots show the diagnostic checks for the EGARCH(2,2) model.
# Residuals plot
plt.plot(egarch22_fit.resid)
plt.title("EGARCH(2,2) Residuals")
plt.show()

# ACF/PACF of residuals
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
plot_acf(egarch22_fit.resid, ax=axes[0])
plot_pacf(egarch22_fit.resid, ax=axes[1])
plt.tight_layout()
plt.show()

From the residual plot, we can see that the residuals of the model are approximately normally distributed and have constant variance over time. Additionally, the ACF and PACF plots of the residuals show no significant autocorrelation, indicating that the model has captured all the relevant information in the data.
Forecasting
The EGARCH(2,2) model provides a volatility fit for the MSFT stock price. Notably, there were spikes in volatility around the start of COVID in 2020 and during the Fed’s interest rate increase in 2022.
# Plot conditional volatility
plt.plot(egarch22_fit.conditional_volatility)
plt.xlabel("time")
plt.title("Conditional Volatility")
plt.show()

Finally, let’s use the EGARCH(2,2) model to forecast the volatility of the MSFT stock price for the next day.
# Last 5 days of volatility
egarch22_fit.conditional_volatility[-5:]
Date
2023-05-08 00:00:00-04:00 0.017646
2023-05-09 00:00:00-04:00 0.016606
2023-05-10 00:00:00-04:00 0.015939
2023-05-11 00:00:00-04:00 0.016860
2023-05-12 00:00:00-04:00 0.016005
# Forecast next day
forecasts = egarch22_fit.forecast(reindex=False)
print("Forecasting Mean variance")
print(egarch22_forecast.mean.iloc[-3:])
print("Forecasting Residual variance")
print(forecasts.residual_variance.iloc[-3:])
Forecasting Mean variance
h.1
Date
2023-05-09 00:00:00-04:00 0.001541
Based on the model, the forecasted volatility for the next day is 0.001541. This value suggests that the average volatility will decrease compared to the last five days. However, the accuracy of this prediction remains uncertain. To assess the model’s accuracy, a rolling prediction approach can be used and compared against actual values using a measure like RMSE. Further analysis will be explored in the subsequent parts of this series.
References
- Tsay, R.S. (2010) Analysis of Financial Time Series, Third Edition. Wiley.
- “Introduction to ARCH/GARCH Models”. ARCH Documentation. Retrieved from https://arch.readthedocs.io/en/latest/univariate/introduction.html.
















